Python解析Pcap文件获取网络流量
要想通过python来解析Pcap文件,首先得了解pcap文件的格式。
Pcap文件格式
从宏观上来看,Pcap文件的格式非常简单,前24字节属于Pcap文件的头部,后续内容全是网络报文的内容:

而Packet Data也分为两部分,前16字节为Packet Header(包含Packet Data的长度),剩下来的长度内容都是Packet Data,如下所示:

所以整体的格式为:

当我们了解了Pacp文件大体格式后,我们来进一步看看24字节的Pcap Header都包含了哪些信息。
Pcap Header
Pcap Header主要包含了7个字段,如下:
- Magic(4B):标记文件开始,并用来识别文件和字节顺序。值可以为0xa1b2c3d4或者0xd4c3b2a1,如果是0xa1b2c3d4表示是大端模式,按照原来的顺序一个字节一个字节的读,如果是0xd4c3b2a1表示小端模式,下面的字节都要交换顺序。现在的电脑大部分是小端模式。
- Major(2B):当前文件的主要版本号,一般为0x0200
- Minor(2B):当前文件的次要版本号,一般为0x0400
- ThisZone(4B):当地的标准事件,如果用的是GMT则全零,一般全零
- SigFigs(4B):时间戳的精度,一般为全零
- SnapLen(4B):最大的存储长度,设置所抓获的数据包的最大长度,如果所有数据包都要抓获,将值设置为65535
- LinkType(4B):链路类型。解析数据包首先要判断它的LinkType,所以这个值很重要。一般的值为1,即以太网
Packet Header
Packet Header可以有多个,每个数据包头后面都跟着真正的数据包。以下是Packet Header的4个字段含义:
-
Timestamp(4B):时间戳高位,精确到seconds,这是Unix时间戳。捕获数据包的时间一般是根据这个值
-
Timestamp(4B):时间戳低位,能够精确到microseconds
-
Caplen(4B):当前数据区的长度,即抓取到的数据帧长度,由此可以得到下一个数据帧的位置。
-
Len(4B):离线数据长度,网路中实际数据帧的长度,一般不大于Caplen,多数情况下和Caplen值一样
Packet Data
Packet Data是链路层的数据帧,长度就是Packet Header中定义的Caplen值,所以每个Packet Header后面都跟着Caplen长度的Packet Data。
也就是说pcap文件并没有规定捕获的数据帧之间有什么间隔字符串。
而Packet数据帧部分的格式就是标准的网络协议格式了。
代码编写
为了获取到每帧报文的raw data,我们首先忽略掉Pacp Header,然后读取到的前16字节即为Packet Header的内容。
从Packet Header内容中,拿到当前报文内容的长度curPacketRawDataLength,然后偏移16字节,读取报文内容,最后继续偏移curPacketRawDataLength字节,循环。
最终的代码如下:
1 | def getFileBytes(filename): |
结果如下:
WireShrk中报文第一条记录: 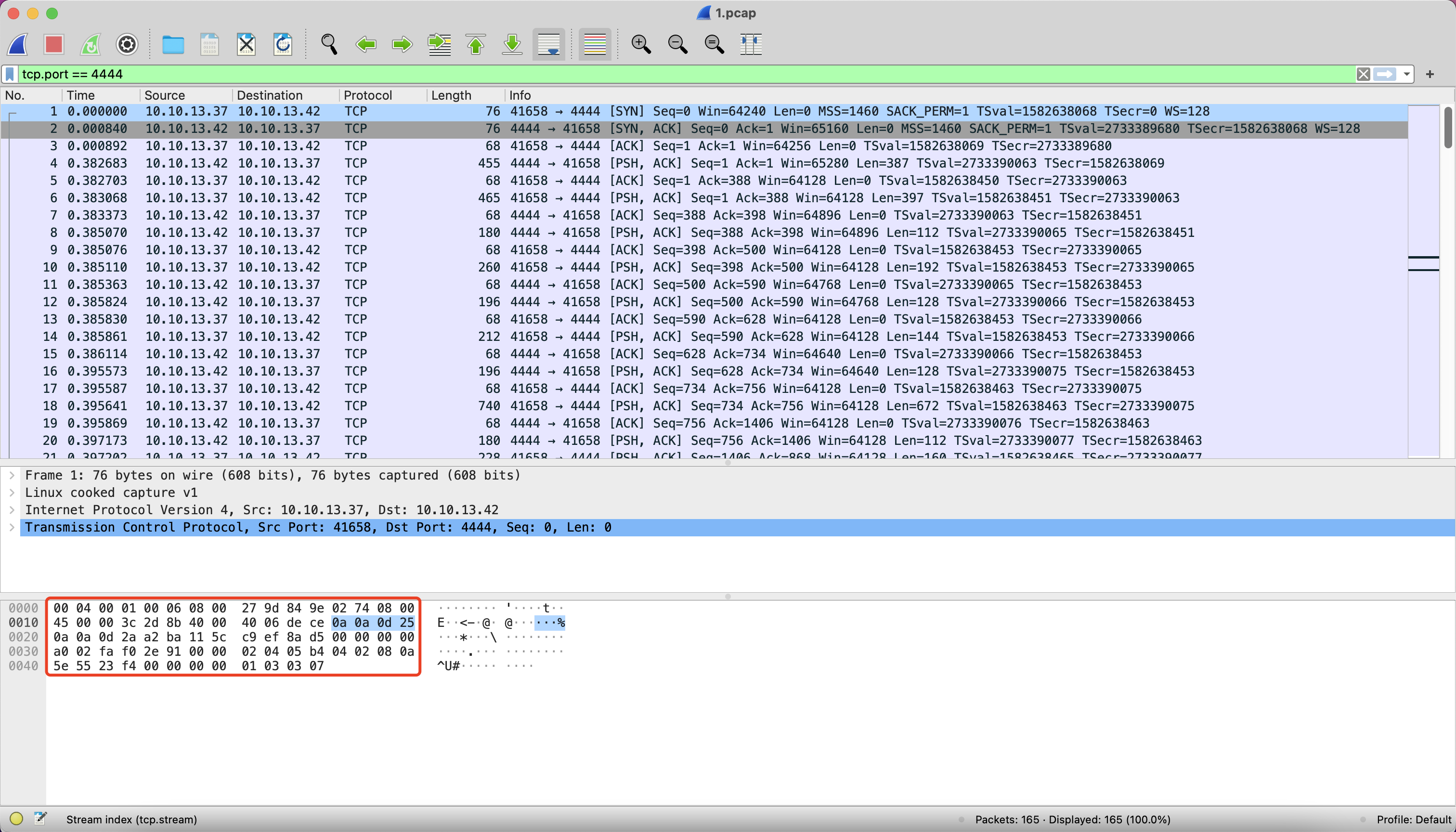
Python解析Pcap后的结果: 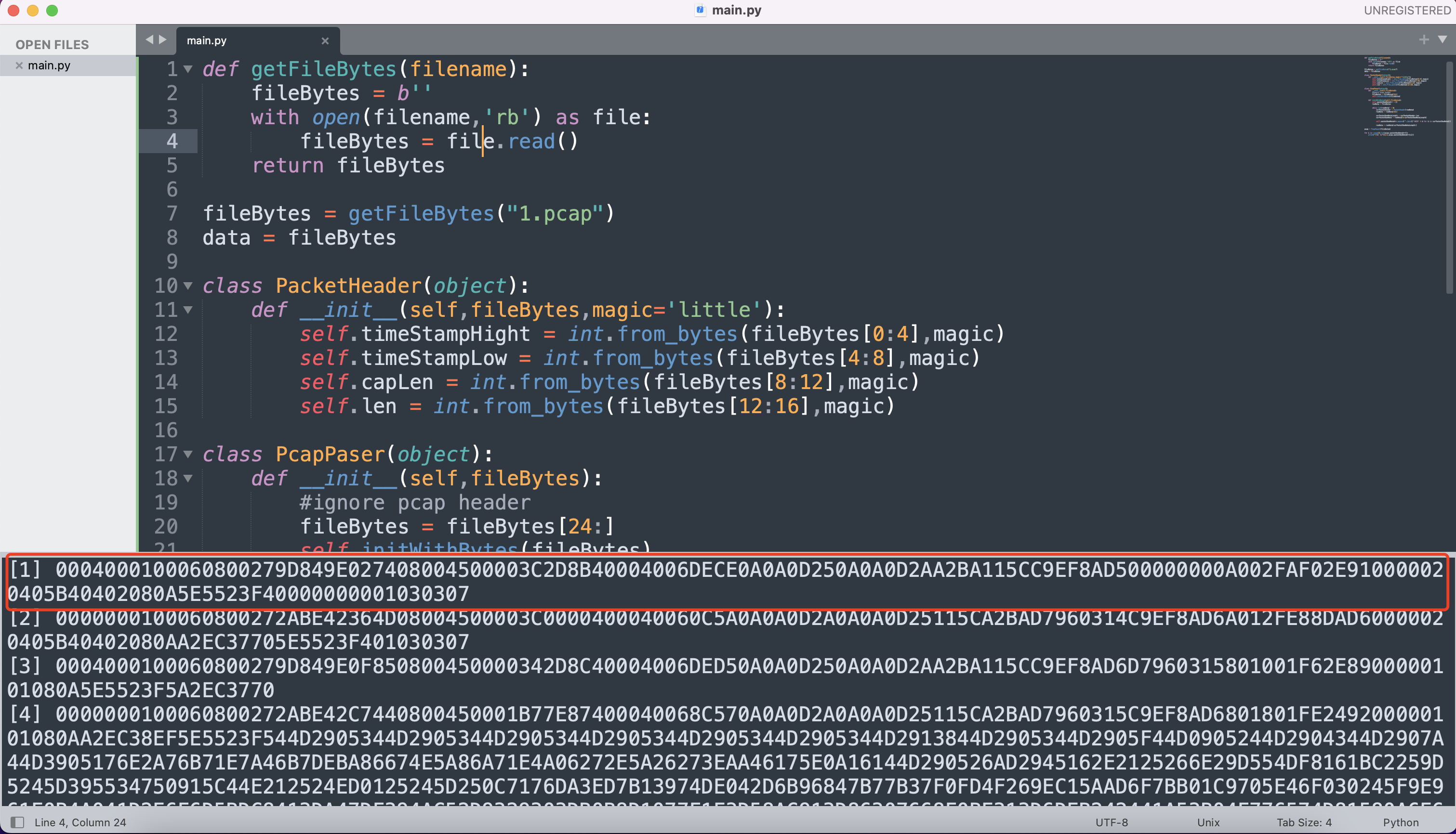
后续还需要解析TCP报文,根据各种情况做过滤,拿到下载zip文件报文的meterpreter流量的raw data,最后解密meterpreter流量还原出zip文件…