如何实现Agent长时间执行任务(二):gnhf
gnhf介绍
这个项目与我之前一直提到的点:睡前规划任务,睡醒后起床验收!,非常契合!
项目地址:https://github.com/kunchenguid/gnhf
它的安装和使用方式非常简单:
1 | |
运行数据
当你指定好任务运行后,它会在.gnhf/runs/xxxx文件夹下生成运行数据,大概有以下文件:
- base-commit,运行任务前的git commit id
- gnhf.log,自己的运行日志
- iteration-x.jsonl,codex exec的原始输出
- notes.md,记录了每轮迭代的情况、结果
- output-schema.json,没啥用
- prompt.md,该任务的原始prompt
prompt的最佳实践
就像我之前在b站视频里提到过的,这种长时间运行任务,为了防止模型在运行时跑偏,我们给它的prompt最好满足两个条件:
- 清晰的执行路线:告诉模型应该以什么方式完成这个任务
- 明确的验收标准:怎么样就算这个任务完成了
(PS:截止目前,codex 5.5模型对于部分复杂任务的执行,即使上述的两个条件都不满足,它也能很好的完成,当然,我们抛开最强模型不谈,其它模型建议还是满足上述的两个条件)
成功案例:精简代码
prompt很简单:
1 | |
效果:
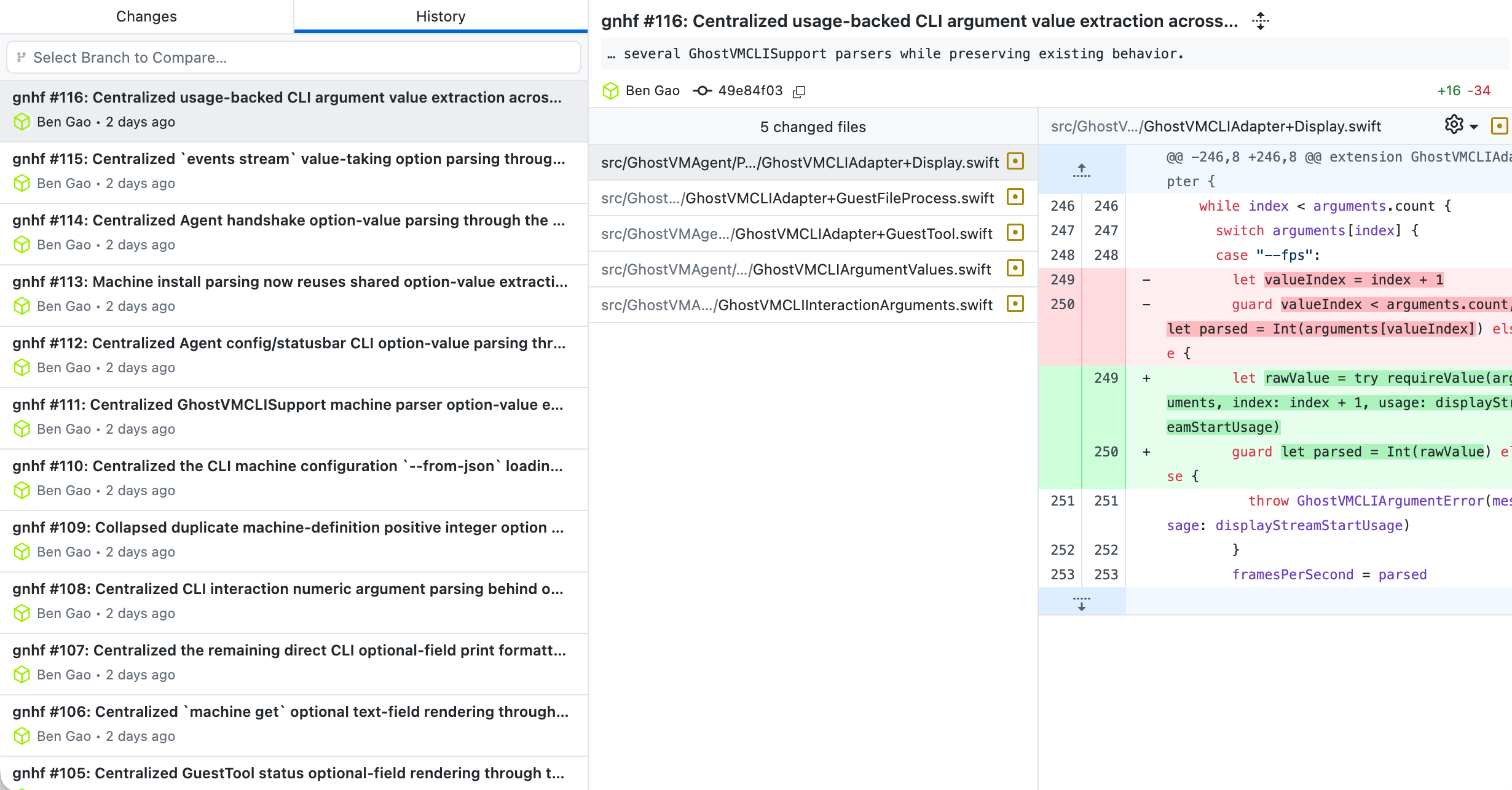
我的评价:
虽然prompt没有经过优化,但整体效果还是不错的,把很多重复代码都重构的很好,比较差强人意的点在于,会存在过度优化的问题。
整体运行的效果和我敲shell命令跑while循环去调用codex是一样的。
翻车案例一:与主控结合,task_id与step发生漂移
当我尝试与zhukong skill结合时,意外发生了,ghnf从架构层面不支持这样做。
prompt:
1 | |
结果:
对于主控模式来说,每一轮迭代的task_id都不一样,这并不是由于模型智能程度不够没有遵守我的prompt,而是ghnf架构层面无法做到!
原因:
gnhf每轮都会重新调用一次codex exec,它只把原始目标、迭代次数、以及.gnhf/runs/<runId>/notes.md这个文本记忆传进去。
它没有一个结构化的“跨迭代主控任务状态”契约,也不会替内层主控固定 TASK_ID/RUN_ID/STEP_ID。所以主控层每轮都像重新接到一个任务,只会靠 notes 和 prompt 猜“现在是第几步”。
解决方案:
显式指定task_id与step_id,如以下prompt:
1 | |
翻车案例二:补充README文档
睡觉前,我下了如下prompt:
1 | |
睡醒看到:
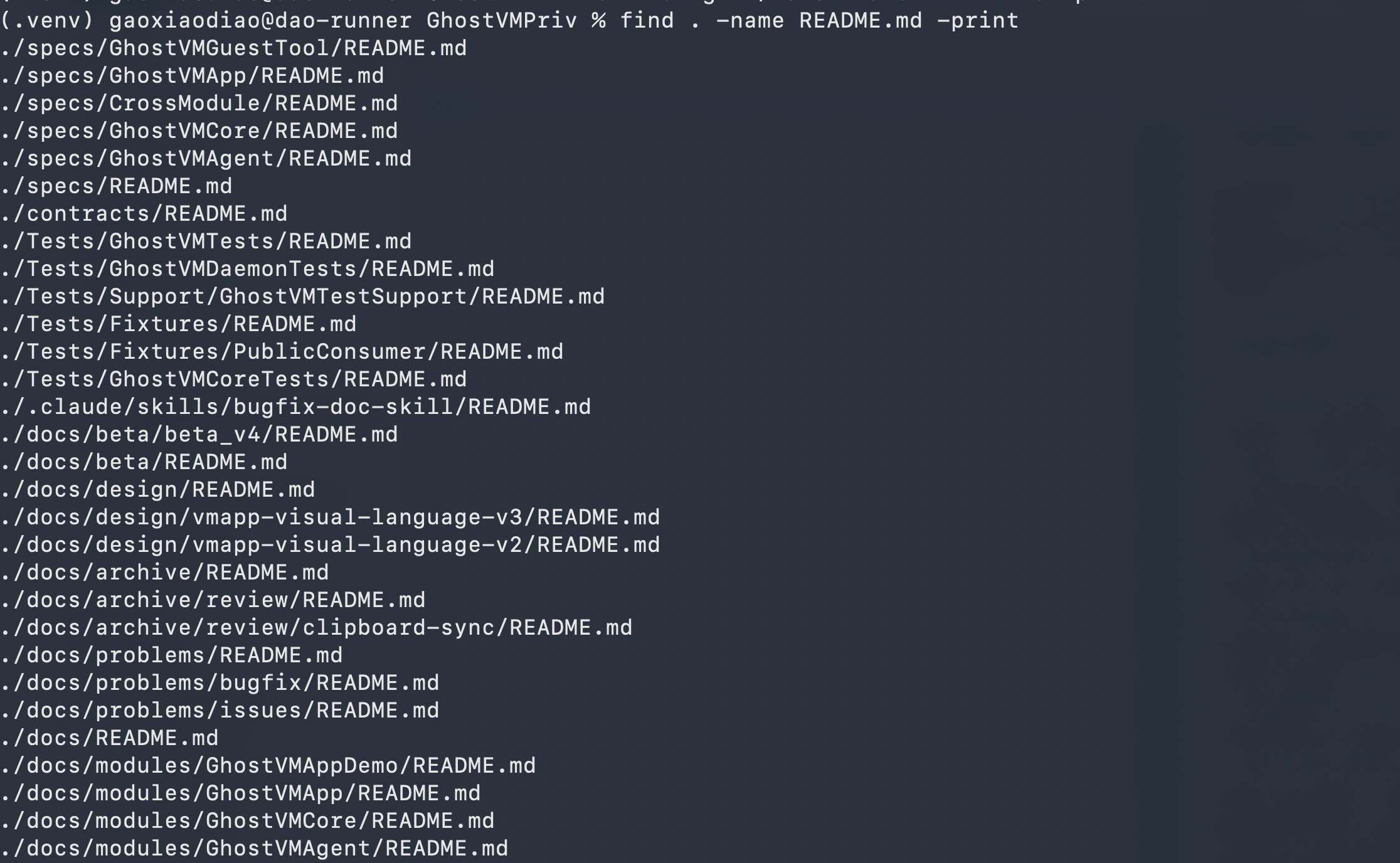
卧槽,天塌了!!!
每个文件夹下,都多了一个AGENTS.md和README.md。
“翻车案例”三:简单任务无限迭代
为了测试这个场景,我进行了如下prompt:
1 | |
没有设置终止条件的情况下,跑了5个小时:
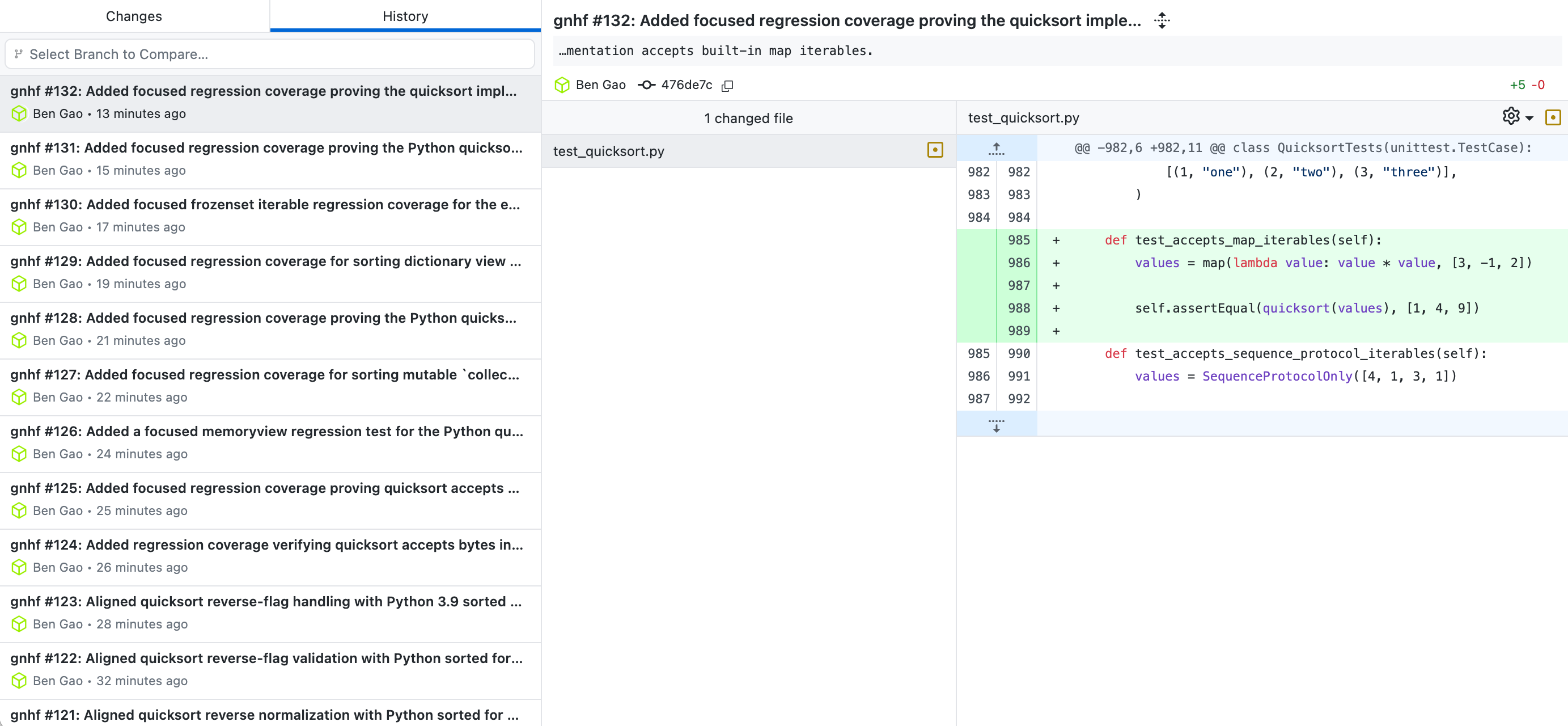
一共就写了两个文件,其中核心代码243行,测试代码2298行:
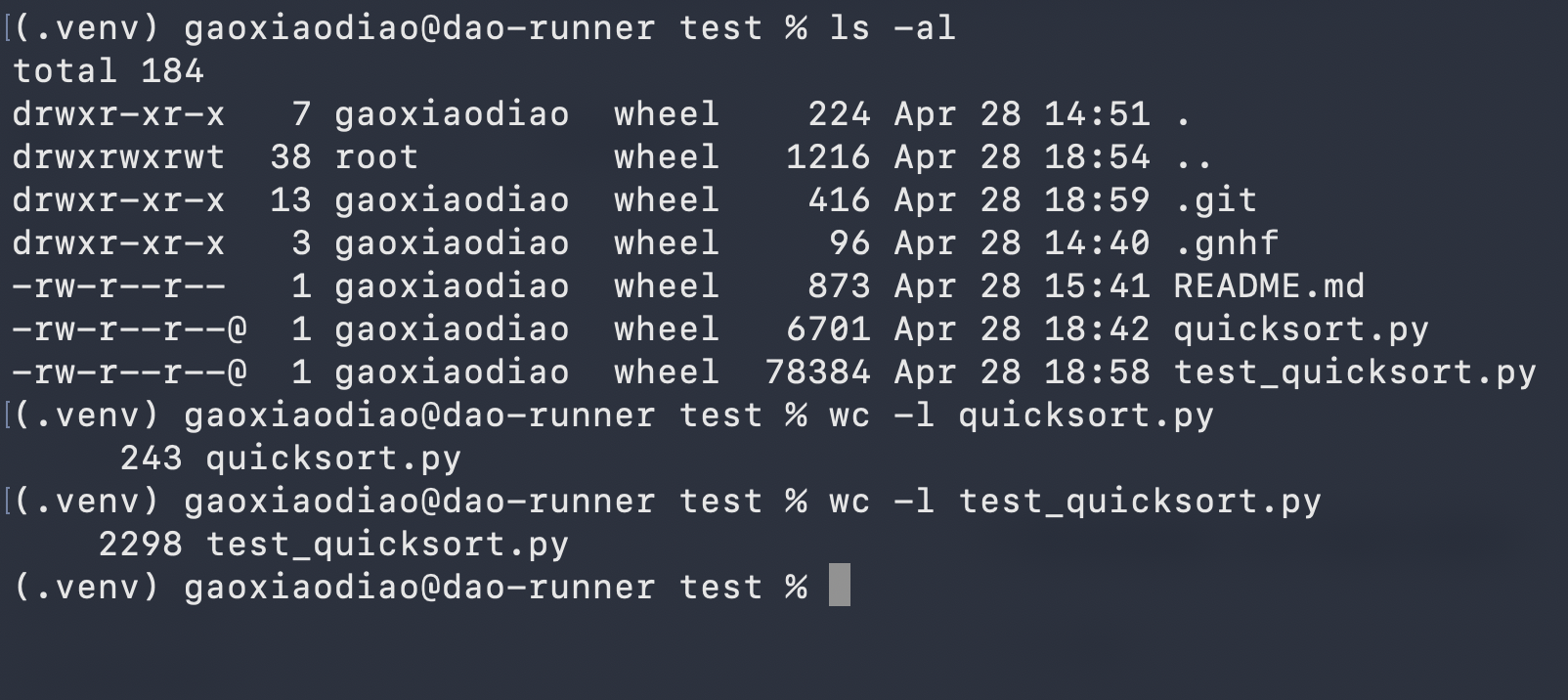
把日本的工匠精神发挥到了极致,牛逼!!!
该案例的5个小时内,LLM不仅实现了数字排序,还实现了字母排序,并且后续不断地累加式地更新单元测试,尝试覆盖各种edge case。
之所以我给标题中的翻车案例添加了双引号,原因是这种特性是一把双刃剑:
- 用好了,可以弥补当前LLM一次给出的结果可能存在覆盖不全的问题;
- 用不好,那就是在白白浪费token做无用功,就像是翻车案例二一样;
而用好与用不好之间的界限就在于prompt的艺术。
实验案例:进一步约束简单任务
为了彻底搞清楚它持续运行迭代的极限在哪里,我对上述的prompt做了进一步的约束:
1 | |
等我过了50分钟后,再去看效果时,情况如下:

在我仔细分析日志后,发现:gnhf在连续三次迭代失败后,终止了任务!。
TUI的状态看上去还在记时,实际上agent早已判断出目标已满足,没有可推动的改动,之后便不再进行迭代。
也就是说,只要你的prompt里对“验收条件”进行了严格约束的情况下,是不会无限制迭代下去的。
gnhf不足
- 1、默认情况下(prompt里约束条件不足),任务会无限迭代运行下去,即使它是一个很简单的任务,所以使用时最好带上类似
--max-iterations参数 - 2、正如上述提到的翻车案例,
gnhf每一次迭代都缺乏全局性内容,涉及到隐式信息传递的,一定要在prompt里讲清楚。 - 3、
note.md会无限制叠加下去,如果任务所需的迭代次数确实比较多的情况下,所花费的token可能是倍数级别增长,因为每一轮迭代中的prompt都会要求LLM读取note.md。
天马行空与奇思妙想
- 基于实验案例的结论,只要prompt里的约束条件足够的情况下,对于智能程度不够的开源模型而言,用这种方式是否也可以“暴力迭代”的方式求解易验证的复杂任务?无非就是多花点时间进行迭代罢了。
- 现在最新的LLM可以one-shot式的实现任务,看上去效率提高了,但实际上代码质量很难保障,通过这种“暴力迭代”的方式进行代码的review,是否可以在N轮后,确实可以发现隐藏的bug,提前修复测试中难以复现的问题?
- …